
Photo by Massimiliano Morosinotto on Unsplash
I am searching for “principles” to use when explaining how to model. I want to distill them from my experience modeling with many disciplines. Some principles, I suspect, are out of my conscious awareness. My actions reflect my principles. How do I uncover these principles from these actions? I’ll describe an approach, one that you can use to share your expertise.
I turned to the Mind-to-Muscle pattern in Neuro-Semantics for help. This pattern takes principles you like and then embeds them within yourself. Then you can follow them with little thought. It is as if your muscles themselves know and act on the principles. It closes the knowing-doing gap. This pattern goes in the opposite direction from my needs since I want to close the doing-knowing gap. Yet, it provided a starting point.
You follow the Mind-to-Muscle pattern by first stating the principle. Then, you describe it as a belief, decide to use it, and express your feeling about your decision. The last step is to state your next action to make the “principle” real in your life. Using the Mind-to-Muscle pattern as a guide, I reversed it in spirit. I thought of actions that seemed related and explored my decisions and beliefs on why I did them. Then, I searched for a principle that they might follow from.
Modeling Principles

Photo by Austin Distel on Unsplash
What are principles? Principles are propositions that guide actions. For our purposes, start each principle with a verb. You don’t need to state principles in the positive or from a particular perspective. For example, “Don’t make me think” is Steve Krug’s principle of usability and web design. For a principle to be useful to others, we need to show how to apply it. To do this, use stories that reflect key concepts and beliefs related to the principle.
“Modeling principles” need to align with your purpose in modeling. My usual purposes are solving a problem and learning something new. I also like to gain enough insight to make predictions or decisions. It is a plus if the model results surprise me. You may have other purposes.
Principle 1 – Look in places no one else does.
I was desperate to find a dissertation topic after coming back to graduate school. It was 1971, and I felt I had wasted the previous two years while in the army. I chose Max Dresden as my PhD dissertation advisor because I loved his style and approach to Physics. He agreed to be my advisor if I could find a dissertation topic on my own. That was my challenge! Here is what I did.
Looking on the Preprint Bin
In graduate school, I trolled the preprint bin. It is where you find papers that were not peer reviewed, accepted or published. Another graduate student saw me and told me I was wasting my time since the papers were old. But I found a paper that led me to write the first half of my dissertation. It was about using symmetry to solve a complicated equation.
Looking in a Science Magazine and then in a Hyperreal Room
The second half of my dissertation was on a strange topic. I found a Science News article on a mathematics called Non-Standard Analysis (NSA). It created a world of hyperreal numbers where infinitesimal and infinite numbers existed. I thought I could apply it to physics. That led to a team effort with Max and another student. We proved thermodynamic behavior follows from microscopic behavior. It was not a new result, but one done with a radical approach. How did we do it?

Door Photo by Dima Pechurin on Unsplash
We had a complicated problem to solve. Imagine opening a door and taking the problem to a room where solving it became much easier. If you looked in our room, you would find it contained infinitesimal numbers. I call it the hyperreal room. We solved our problem using the tools in the room. Then, we returned the resulting solution back through the door to the “real” world. NSA calls the ability to go through the door with a solution the “transfer principle.” Using NSA with success surprised me.
Understanding how a principle relates to your actions helps you explain how to use it. Using Principle 1, I asked: “What are the beliefs holding my actions in place?” In his book, “Seeing What Other’s Don’t”, Gary Klein discusses “creative desperation.” He says there are situations “… where people reach an impasse and need to reexamine their assumptions to break free.” When I thought more about my actions, I realized something I had forgotten. I would lose the opportunity to work with Max if I did not find a dissertation topic. Someone else would take my place.
Desperation led me to do more than necessary. I found four topics leading to five published papers before I graduated in 1977. Two were enough for a dissertation. Sometimes you need to turn off the principle. All of this rested on my belief: “Look where no one else looks to see what others don’t. As a result, gain a competitive edge.”
Principle 2 – Apply models from one discipline to gain modeling insights in another one.
Many people stay within one discipline and don’t get new perspectives from other ones. Some people may never get away from the “not invented here” mentality. Here are two examples where I used Principle 2.
 Emotions
Emotions
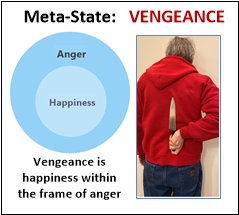
In his book, “The Problem of Emotions in Society”, Jonathan Turner says you feel complex emotions when you mix primary ones. Each emotion can have a different intensity. It is like mixing colors. You get cyan when you mix blue and green. Turner says vengeance arises when you mix more anger than happiness. But the Meta-States model provides a richer perspective. There, vengeance brings the frame of anger with its beliefs and applies it to happiness. It is not about the anger being more intense than happiness. I brought Neuro-Semantics to bear on sociology.
Maya Collapse Project.
I am working on a system model of the ancient Maya. My colleagues and I are using “disease models” to understand the classic Maya collapse. Instead of using a medical disease, we use “warfare.” We model how warfare acts like a virus contributing to the collapse.
Closing the Gap

Photo by Guillaume de Germain on Unsplash
After reading Principle 1, did you think of the challenge: “NO ONE? I am sure other people look in preprint bins and magazines for ideas?” I could have stated the principle as: “Look in places most people don’t.” This version lacks the power of the original. Avoid adding “conditions” or wishy-washy “qualifiers” to principles. They weaken the principle. Be assertive!
Once you have principles, use the Mind-to-Muscle pattern to refine and test them. My approach to searching for principles can help anyone with experiences to share. What are the principles underlying your expertise?
References and Further Reading
Gambardella, Pascal. 2021. “Mind-to-Muscle Mindmap.”
Gambardella, Pascal. 2018. “Three Doors into Summer: Bringing one World to Bear on Another.”
Gambardella, Pascal J. 1975. “Exact Results in Quantum Many‐Body Systems of Interacting Particles in Many Dimensions with SU(1,1) as the Dynamical Group.” Journal of Mathematical Physics 16, no. 5: 1172-87.
Ostebee, A., P. Gambardella, and M. Dresden. 1976. “Nonstandard” Approach to the Thermodynamic Limit.” Physical Review A 13, no. 2 878-81.
Ostebee, A., P. Gambardella, and M. Dresden. 1976. “A ’’Nonstandard’’ Approach to the Thermodynamic Limit. II. Weakly Tempered Potentials and Neutral Coulomb Systems.” Journal of Mathematical Physics 17, no. 8:1570-78.
Hall, L. Michael. 2004. “Mind-to-Muscle” in The Sourcebook of Magic Vol 2, p. 99-100.
Klein, Gary. 2013. Seeing What Others Don’t: The Remarkable Ways We Gain Insights.
Krug, Steve. 2014. Don’t Make Me Think, Revisited.
Kyriacou, Jimmy 2004. “Meta-Stating Wisdom.” In The Sourcebook of Magic Vol 2, L. Michael Hall, page 215. This pattern reverses the Mind-to-Muscle pattern.
Turner, Jonathan. 2011. The Problem of Emotions in Society.
Acknowledgements
I want to thank Claire Kurs for her editorial feedback and for taking the photo in the vengeance image
Views: 98
 Pascal is a master modeler, who has modeled physical phenomena, satellite motion, and the behavior of people, organizations, and corporations.
Pascal is a master modeler, who has modeled physical phenomena, satellite motion, and the behavior of people, organizations, and corporations.